
MonitoringPortalにおけるホスト・サービス障害通知
MonitoringPortalでは、監視結果が正常でない場合でも、何度かテストを繰り返した上で、段階的な通知やサービス再起動を行います。そのため、一時的な負荷やネットワークの接続状態の度に、誤検知での通知を受ける事はほとんどありません。必要な情報のみを通知することで、担当者が通知を見逃すリスクも最小限に抑えることができます。
ホスト障害やリソース変化時の通知の流れ
ホストの状態は、定常時は10分に一回づつ監視しています。デフォルトではpingでの通信確認となりますが、プロトコルの変更も可能です。また、CPUの稼働状況やディスクの使用状況なども、同時に監視しています。
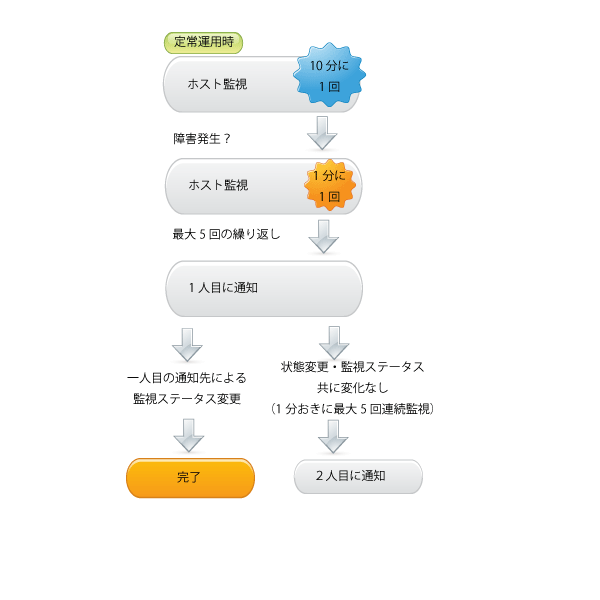
確認コマンド実行後、値が正常値でない場合(ディスク使用量が90%を超えた場合など)や、pingの応答がなかった場合、10分に一回づつではなく、1分に一回づつ、5回監視を繰り返します。これでも値が正常と判断できない場合は、障害発生とみなし、1人目のご担当者様宛に通知を行います。通知の手段として、電子メール/Twitterをご利用頂けます。
通知を受け取ったご担当者様は、ブラウザから管理画面へアクセスし、障害に関するログをご確認頂けます。「この問題は確認済です」というステータス変更ボタンをクリックすると、障害通知は完了したものと判断され、その後の通知やコマンド実行は行われなくなります。
障害の状況に5分経過しても変化がなく、且つ、管理画面からステータスの変更も行われなかった場合は、2人目のご担当者様や携帯のメール宛に、次の通知が行われます。
サービス障害通知の流れ
サービス障害は、ホスト障害と依存関係を持って監視されています。例えば、サーバー機そのものが障害で停止していた場合、そのサーバー上で稼働しているサービスは、当然稼働していない状態となります。こうした場合、障害は、サービス障害ではなく、ホスト障害とみなされ、ホスト障害の通知のみが行われます。2重の通知を防ぐことで、障害の原因を特定しやすくなっています。
サービスの状態は、定常時は3分に一回づつ行われています。サービスは、ポートへのアクセスやプロセスの稼働状況はもちろん、HTTPのステータスやFTPサーバー内のファイルの有無、メールサーバーのセッション数など、サービスに応じた監視も行えます。
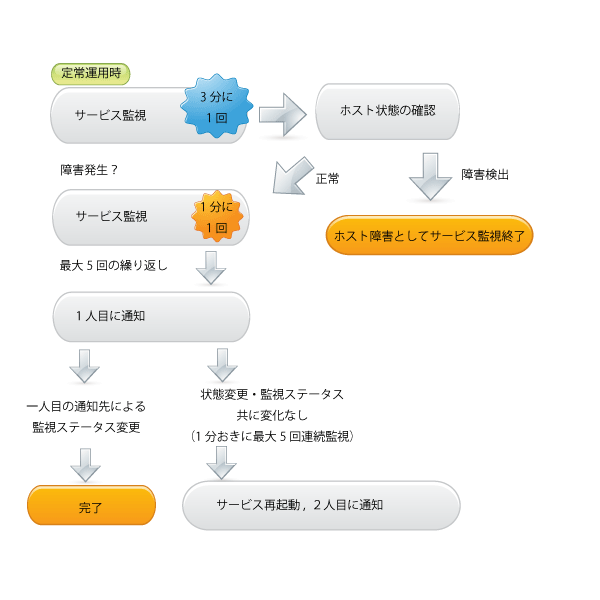
確認コマンド実行後、値が正常値でない場合、まずはホストの監視ステータスを確認します。先ほどご説明した通り、ホスト障害が同時に発生していた場合は、サービスへも当然アクセスできなくなりますが、この時はサービス障害とは判断されず、ホスト障害として処理されます。ホストのステータスが正常ならば次の処理を行いますが、ホスト障害が確認できた場合は、サービスの障害検知はここで完了となります。
ホストは正常であるにも関わらず、サービス確認コマンドの値が正常でない場合(つまりサービス障害が発生している場合)3分に一回づつではなく、1分に一回づつ、5回監視を繰り返します。これでも値が正常と判断できない場合は、障害発生とみなし、1人目のご担当者様宛に通知を行います。通知の手段として、電子メール/Twitterをご利用頂けます。
通知を受け取ったご担当者様は、ブラウザから管理画面へアクセスし、障害に関するログをご確認頂けます。「この問題は確認済です」というステータス変更ボタンをクリックすると、障害通知は完了したものと判断され、その後の通知やコマンド実行は行われなくなります。
障害の状況に5分経過しても変化がなく、且つ、管理画面からステータスの変更も行われなかった場合は、2番目の通知先への通知や、サービスの自動再起動といった、次のアクションが実行されます。